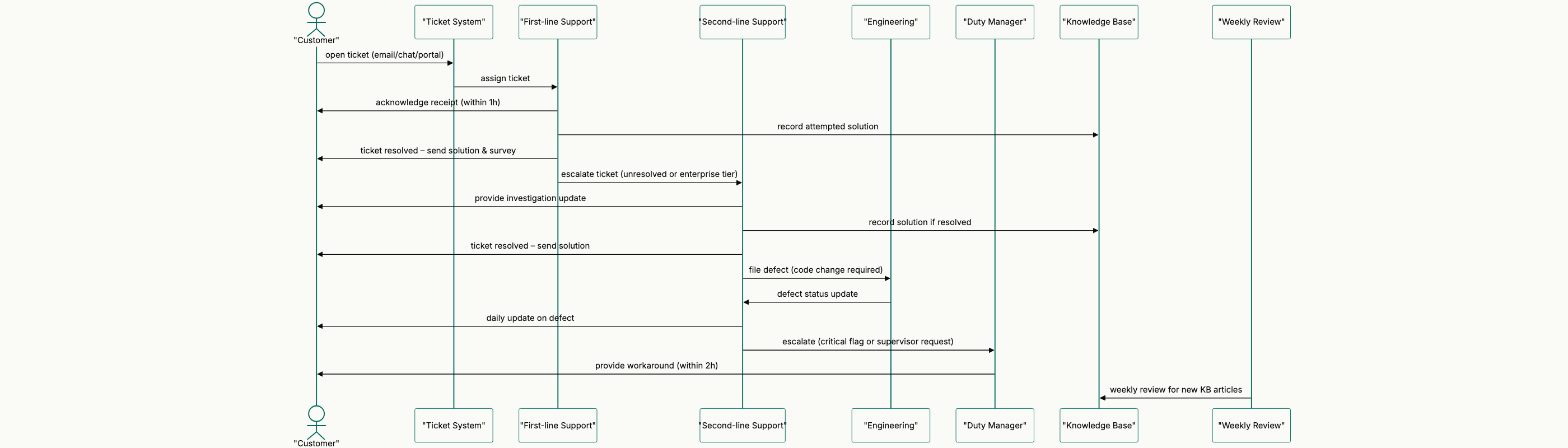
One description, the whole diagram set
From that single description, Storm2Flow generates the diagrams that match it, not just one picture:
- Flowchart: the decision paths from detection through triage, escalation, and resolution, with the severity branches made explicit.
- Swimlane: who owns each step, so the handoff between first-line, second-line, and engineering is unambiguous.
- Sequence diagram: the escalation conversation over time, including the customer-communication touchpoints.
- BPMN: a standards-based model when you need to align with a wider operations or compliance practice.
- Mind map: the whole response at a glance, useful for onboarding a new responder.